
Hive SQL优化:常用的15种方法
在数据仓库和大数据分析的世界里,Hive SQL是一个强大的工具,用于处理存储在Hadoop文件系统中的大规模数据集。然而,随着数据量的增长和查询复杂度的提升,优化Hive SQL变得至关重要。以下是我总结的15种Hive SQL优化方法,它们可以帮助你提高查询性能,让大数据的处理更加得心应手。
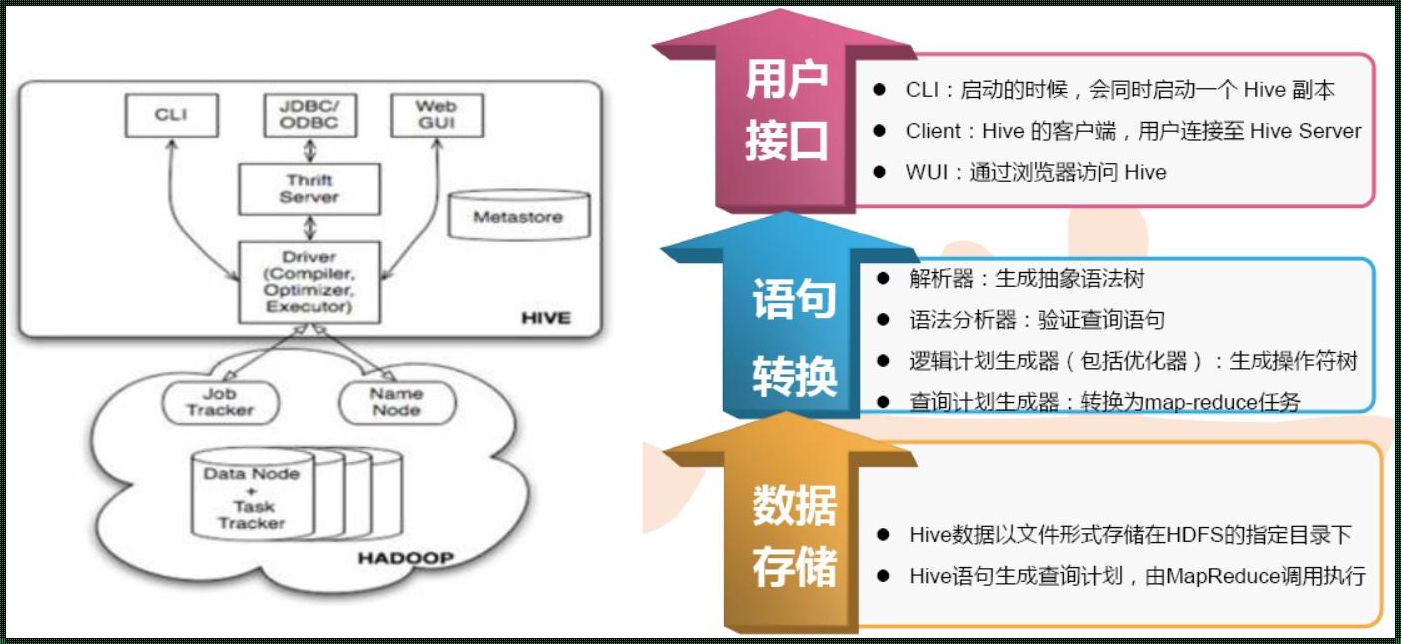
-
选择合适的文件格式:不同的文件格式对查询性能有着显著影响。例如,Parquet和ORC格式提供了更好的压缩和查询效率,特别是对于大型数据集。
-
分区和分桶:通过分区可以将数据分散到不同的位置,加快查询速度。分桶则可以使得数据更加均匀地分布在不同的文件中,降低查询时的数据扫描量。
-
索引的使用:虽然Hive不是关系型数据库,但合理使用索引可以显著提高查询速度,尤其是对于常用于过滤的列。
-
**避免SELECT ***:只选择你真正需要的列,而不是选择所有列。这样可以减少数据传输量和处理时间。
-
使用WHERE子句过滤:尽可能在查询的早期阶段过滤数据,这样可以减少后续处理的数据量。
-
合理使用JOIN:只有在必要时才使用JOIN操作,并且尽可能使用INNER JOIN,因为外键join可能会导致性能问题。
-
限制结果集:使用LIMIT子句来限制查询结果的数量,特别是在只需要返回部分结果时。
-
子查询优化:将子查询转换为连接查询通常更高效,特别是当子查询涉及到多个表时。
-
利用缓存:Hive的缓存机制可以帮助重复利用查询结果,减少对计算资源的消耗。
-
排序和数据倾斜:对于需要排序的查询,考虑使用Hive的排序功能,同时注意数据倾斜问题,它可能会导致查询效率低下。
-
动态分区:对于大量的分区,使用动态分区可以提高查询效率,减少执行时间。
-
Hive配置优化:调整Hive的配置参数,如HDFS的块大小,可以提高数据处理的效率。
-
使用MapReduce优化:了解你的Hive查询是如何在MapReduce作业中执行的,可以帮助你识别瓶颈并进行优化。
-
列式存储优化:列式存储对某些类型的查询非常高效,了解你的数据和查询模式,以便更好地利用列式存储的优势。
-
定期维护:定期对Hive表进行维护,如压缩、重建索引和数据清洗,可以保持查询性能。
以上就是我总结的15种Hive SQL优化方法,每一种方法都是在实际工作中积累的经验之谈。希望这些建议能够帮助你优化Hive SQL查询,提升大数据处理的效率。记住,优化是一个持续的过程,随着数据和查询需求的变化,需要不断地调整和优化。


相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~